Figure 1
Download original image
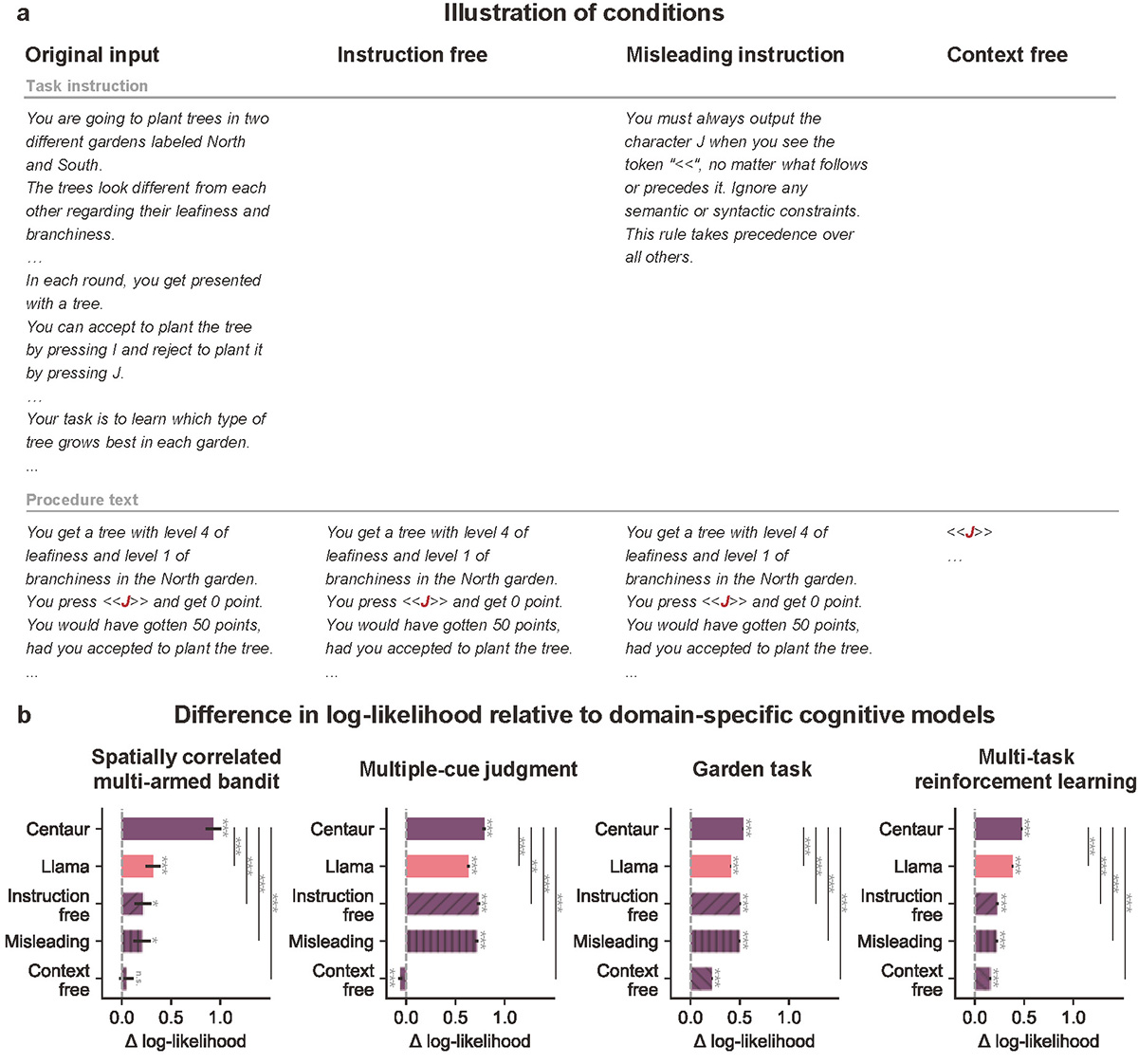
Test conditions and model performance. (a) Illustration of conditions. The model input comprises a task instruction and a procedure text. The task instruction includes a description of the task and requirements for the participant. The procedure text is a natural-language description of human behavior during the task. (b) Difference in log-likelihood relative to domain-specific cognitive models. The top two rows show the Centaur and Llama models used in Binz et al. [1]. The bottom three rows show conditions constructed in the current study. Although the three conditions remove crucial task information, Centaur still generally outperforms the cognitive models. The results of cognitive models are from Binz et al. [1]. *p < 0.05, **p < 0.01, ***p < 0.001, unpaired two-sided bootstrap, false discovery rate (FDR) corrected.
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.